The heat got turned up this week and we looked at keywords, looked deeper at collocation and colligation and then semantic preference and discourse prosody.
As somebody always about in the internet and reading blogs about teaching, I have kind of got sick of the definition of collocate as ‘the company words keep’. It doesn’t really mean very much, and it could even apply to colligate, too.
Collocate: words that statistically occur together.
Colligate: words that have a statistical affinity for grammatical classes.
Then we get onto semantic preference. This is really interesting. These are basically collocate groups. For example, in a search of the BNC for ‘encounter’ as a noun there are a collocations with: this, first, last, final, after, second, before, every. I would say (and I could be wrong) that this forms a semantic group of chronological markers.
What this means for teachers is that if you plan to teach ‘encounter’ as a noun, you should probably consider teaching it in contexts with these markers, probably as part of a story. This could be part of a prior reflection on words likely to arise as part of a task in a syllabus or, if you’re teaching using literature, that you might want to bring in some other materials if these collocates don’t appear (although there are also collocates with ‘casual’, ‘sexual’ and ‘thrilling’ for all you risque teachers).
Getting on to discourse prosody, which is the meanings and discourse usually associated with words, this basically has sociolinguistic implications in that how a word is used within a corpus (especially one taken at a specific time/place) tells you about the cultural values associated with that word. Again, in the BNC, if one searches for ‘elderly’ that it appears they need care, particularly health care and that they are vulnerable, which is also backed up by collocations.
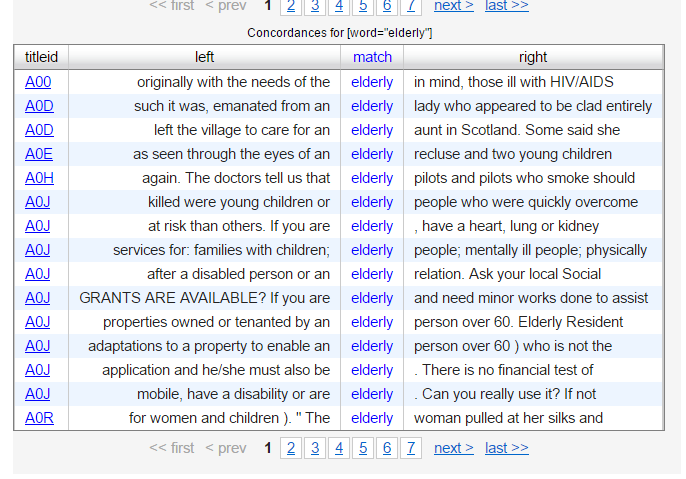
For teachers, this means you might look at this word (for recycling especially) when teaching lessons based on health, or talk about health and infirmity when talking about age (and whether these should be taken as a given, of course; always question discourse!)
I haven’t had much time to play with AntConc this week because I want to make a better corpus to mess about with. Still, interesting stuff.
Tag: mooc
#CorpusMOOC Week 1 notes
I joined the Futurelearn/Lancaster University Corpus MOOC (Massive Open Online Course) this week to supplement the module on technology and corpus linguistics I’m studying for my MA.
So far, so good. I’ve managed to watch all of the video lectures and I’ve done a good deal of the reading. It’s just a bit of a dip of your toe in the water this week but it was useful to read about different types of corpora as well as how to read the frequency data and so on (spoiler: think of source material and how wide it is).
One thing that did come up that I wanted to reflect upon was something said in one of the lectures:
Corpora may be used by language teachers to check frequency of occurrence so they may decide to teach their learners more high-frequency items.
It sounds right but then what about sequences of acquisition? Sure, single words, especially simple nouns or verbs might be chosen, but could it be the case that some high-frequency structures are acquired later than less frequent ones? I think I have more reading to do!